Hi
A guy on the microsoft.public.biztalk.orchestration newsgroup has asked about looping around elements inside an orchestration, and I thought I'd just write some lines about the issue here, for everybody to see in the future.
The problem is, that he has the following document structure:
<Employees>
<Employee title="mgr">
</Employee>
<Employee title="vp">
</Employee>
<Employee title="ceo">
</Employee>
</Employees>
And he wants to do something with each employee, based on what the title is. As I see it, there are two options:
- Loop through the Employee-elements inside the orchestration
- Use an envelope to split the incoming Employees-message into several Employee-messages
Suggestion 1
I have proposed the following two schemas:
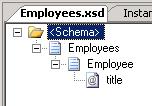 for the big message that arrives and
for the big message that arrives and 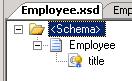 for the individual Employee. Note, that I have promoted "title" as a distinguished field.
for the individual Employee. Note, that I have promoted "title" as a distinguished field.
I then create an orchestration, that takes an instance of the Employees schema as input, and loop around the employees. The orchestration looks like this:
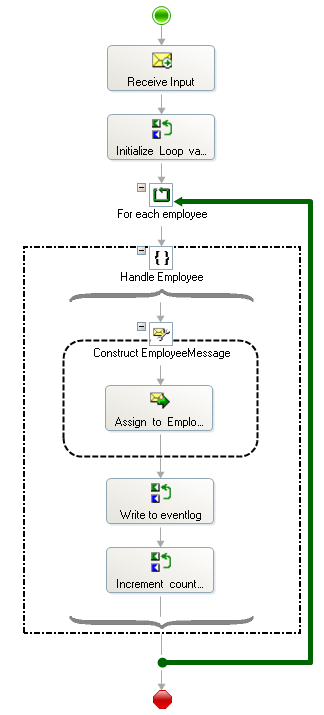
It receives the incoming message, and then initializes a couple of variables. The first expression shape, named "Initialize Loop variables" contains the following three lines:
empCount = xpath(InputMessage, "count(/*[local-name()='Employees' and namespace-uri()='']/*[local-name()='Employee' and namespace-uri()=''])");
counter = 1;
counterStr = "1";
Basically, I get the number of employee-elements, and initialize the counter. The stringcounter is used to build xpath expression later, as you will see.
Then, I loop. The loop condition is "counter <= empCount" - so I want to loop as long as there are employees.
Inside the scope, I have declared a message employeeMessage, which is of the type of a single employee.
In the message assignment shape, I do this:
EmployeeMessage = xpath(InputMessage, "/*[local-name()='Employees' and namespace-uri()='']/*[local-name()='Employee' and namespace-uri()=''][" + counterStr + "]");
It takes the employee from the big incoming message that corresponds to the counter and assigns it to the message that is to be constructed.
In the next expression shape, I just write the content of the distinguished field "title" of the employee to the eventlog.
And in the final expression shape, I increment the counter variables:
counter = counter + 1;
counterStr = System.Convert.ToString(counter);
So by doing this, I am looping over the employees inside the employees-message, and I have access to all the values inside the single employee. I didn't have to have schema number 2, describing a single employee, I could have just used xpath all the way down, or maybe declare an XmlNode variable to hold the employee-element instead. But I like this solution better.
Another option I have now is that I can add a decision shape, and based on the title value, I can call different orchestrations, that will handle a specific employee-type. Or perhaps I could just send the employee message to a direct-bound send port and have other orchestrations subscribe to the employee message type. This would require the title to be a promoted property instead of a distinguished field, though, in order to route on it.
Suggestion 2
I propose using an XML Envelope to split the incoming file into several employee-messages and let the orchestration handle them individually.
To do this, I have created two schemas:
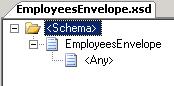 for the envelope and
for the envelope and 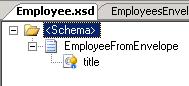 for the employee. Note: I have changed the names of the root nodes in both schemas. Naturally, in real life you wouldn't do this. The only reason I did this is to be able to have both my examples deployed at the same time. If I hadn't done it, I would have had multiple schemas deployed with the same combination of target namespace and root node, which we all know is BAD. On the schema for the envelope, I have clicked on the "<Schema>"-node and in the properties windows, I have set "Envelope" to "Yes". Then, I clicked on the "EmployeesEnvelope"-node and in the properties window, I set the "Body XPath" property to point at the "EmployeesEnvelope"-element.
for the employee. Note: I have changed the names of the root nodes in both schemas. Naturally, in real life you wouldn't do this. The only reason I did this is to be able to have both my examples deployed at the same time. If I hadn't done it, I would have had multiple schemas deployed with the same combination of target namespace and root node, which we all know is BAD. On the schema for the envelope, I have clicked on the "<Schema>"-node and in the properties windows, I have set "Envelope" to "Yes". Then, I clicked on the "EmployeesEnvelope"-node and in the properties window, I set the "Body XPath" property to point at the "EmployeesEnvelope"-element.
Then, I created an orchestration, that takes an employee as the input - not the employees-type, but the single employee. It looks like this:
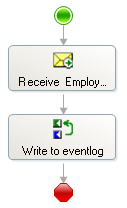
So here I have a much smaller, simpler, and faster orchestration than the one from suggestion 1.
After the solution is deployed, I create a receive location, and remember to use the default XMLReceive pipeline. The disassembler stage will look at the incoming message, determine the message type, see it is an envelope, split the message into smaller messages, and publish them individually with their own message type.
If I need different orchestrations depending on the value of the title attribute, I can promote it to a promoted property instead of a distinguished field, and add it to a filter on the receive shape in each orchestration.
Examples:
I have my two samples here: LoopAroundEmployee.zip (68,66 KB) and here: LoopAroundEmployeeEnvelope.zip (48,64 KB)
I hope this has been useful for someone. If you have any questions, just ask.
--
eliasen