Well, I suppose we have all been there – in order to get the business process running, a specific element from a schema needs to be promoted in order to route on it, correlate on it, and so on.
Unfortunately, elements that can occur more than once can not be promoted. This, off course, makes perfectly sense, since the property can only hold one value, and how would BizTalk know which one of the many occurring elements to take the value from at runtime? So we agree with the limitation, but hope for a nice solution. 
If you try to promote a reoccurring element, you get this error when adding it to the list of promoted properties:

“This node can occur potentially multiple times in the instance document. Only nodes which are guaranteed to be unique can be promoted.”
Right. Now, some people have found the editor for the XPath describing the element that one wants to promote. If you have promoted some element, you can click on it like this:
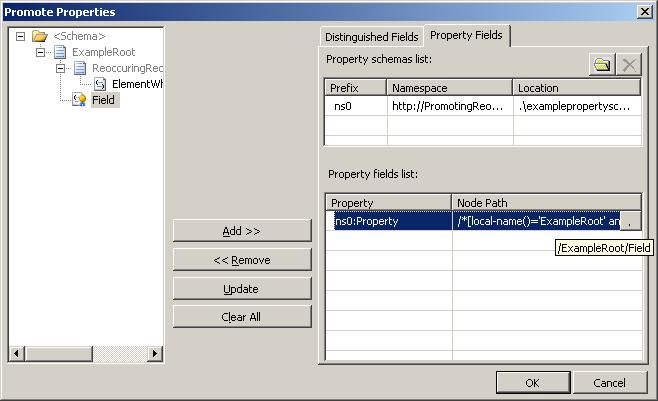
Then you can click on the dot at the right of the line, and get into the editor like this:
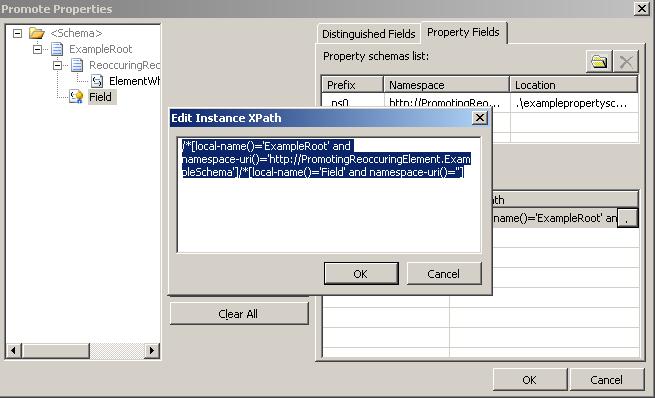
Now, wouldn’t it be lovely, if you could just change this expression to include for instance an index on the reoccurring element? In my example from this screenshot, the “ReoccuringRecord” record can occur multiple times. So it would be nice, if I could just change the XPath to be like this:
/*[local-name()='ExampleRoot' and namespace-uri()='http://PromotingReoccuringElement.ExampleSchema']/*[local-name()='ReoccuringRecord' and namespace-uri()=''][1]/*[local-name()=’ElementWhereNumber1IsPromoted’ and namespace-uri()='']
By setting the “[1]” into the XPath, I state that I will be needing the first occurrence of the ReoccuringRecord and therefore, this XPath expression will always give me exactly one node. Unfortunately, the engine can not see this, so the error will be the same, only difference being that this error doesn’t occur until compile time:
Node "ElementWhereNumber1IsPromoted" - The promoted property field or one of its parents has Max Occurs greater than 1. Only nodes that are guaranteed to be unique can be promoted as property fields.
Bummer!
So how do we get this working? If I really need to promote a value that occurs in an element that might occur multiple times, I see four options:
- Map to a schema on receive port
- Custom pipeline component
- Orchestration to do it and then publish to MessageBox
- Call pipeline from orchestration
I will go these options in more detail here:
Option 1: Map to a schema on receive port.
When a map is executed on a receive port, some extra magic functionality is performed by BizTalk. After the map has been executed, the message is sent through some code that promotes properties that are specified inside the destination schema. If you execute a map inside an orchestration, this doesn’t happen.
So you can create a schema that has an extra field, in which you place the value that needs to be promoted. This element must not be able to occur multiple times. Promote this new field, and after the map on the receive port has been executed, you have your value promoted.
Option 2: Custom Pipeline Component.
It isn’t that difficult to create a custom pipeline component, that can promote a field for you. Your Execute method might look just like this:
public Microsoft.BizTalk.Message.Interop.IBaseMessage Execute(IPipelineContext pContext, Microsoft.BizTalk.Message.Interop.IBaseMessage pInMsg)
{
pInMsg.Context.Promote("MyProp", "http://ReoccuringElement.PropertySchema", "MyValue");
return pInMsg;
}
Of course, you will probably want to load the body stream of the IBaseMessage somehow, in order to find the value inside the body to promote and then replace "MyValue" with the value form within the XML.
Just use the pipeline component inside a custom receive pipeline, and you are all set.
Option 3: Orchestration to do it and then publish to MessageBox
Create a intermediate orchestration, that gets the input message. Then, it should create a new message of the same type in a message assignment shape like this:
NewMessage = InputMessage;
NewMessage(*) = InputMessage(*);
NewMessage(MyNewProperty) = xpath(InputMessage, xpathexpression);
Then, use a direct bound port to publish the message to the MessageBox. In order for the new property to follow the message, you need to initialize a correlation set on the send shape that is based on this new property.
Let other orchestrations and send ports subscribe to this message and let then do their work.
Option 4: Call pipeline from orchestration
The last option is to call a receive pipeline from within your orchestration. This requires a new schema, that has a field for the value to be promoted, just as in option 1. Inside your orchestration, map the input message to this new schema, and call a receive pipeline with this new message as a parameter. Remember to promote the field in this new schema. There is an article on MSDN about calling a pipeline from within an orchestration, which can be found at http://msdn2.microsoft.com/en-us/library/aa562035.aspx
Upsides and downsides
In order to choose which way to go in a specific solution, several things need to be considered.
Basically, I'd go for option 1 almost anytime. This is because it is best practices to map anything incoming into a canonical schema anyway. So instead of promoting values inside all your partners schemas - schemas they might change, you should promote from within your own canonical schema.
Reasons not to choose option 1 include: The canonical schema also has a reoccurring element, so it hasn't provided extra functionality with regards to getting this specific value promoted. Or perhaps, we aren't using canonical schemas, because there was no time for this when the project was started.
If we can't go for number 1, I'd go for number 3. Number 2 requires programming of a pipeline component, which can be a bottleneck, unless done correct. Also, the pipeline component is a whole new component to maintain, document and test. Number 4 requires a new schema and therefore also a map to be built. If I am ready to do this, I'd go for number 1 instead.
If I don't like number 3, for unknown reasons, I'd go for option 2 - the custom pipeline component. Allthough it is custom code, and must be done right, and testet and everything... I still feel that creating a new schema and map in order to call the pipeline in option 4 is overkill, since I'd go for option number 1 instead, which would also require the new schema and map.
I hope this explains some details about this issue, and that it helps someone in the future.
--
eliasen